Which view will you use?
Vertical
For easy reading
Pages
For sectioned pages

For easy reading
For sectioned pages

The search for a panacea, a cure-all that can heal any disease or ailment, has spanned as far as the length of human civilization. Although in the modern day, we understand that existence of a panacea isn’t very realistic, we still strive towards that ideal for perfect healthiness that encompasses all aspects of physical and mental well-being. One of the obstacles faced is that humans have often died from illnesses because they were not caught in time. This could have been caused by missing early signs of cancer, failing to sign up for a yearly checkup, or ignoring current problems that can lead to worse consequences. Oftentimes, people notice the symptoms and the issue resolves itself. However, in the cases where they do not, they can be fatal. The first step towards that ideal of a panacea is identifying all diseases accurately and quickly so that treatment can be done as soon as possible and prevent further complications or death.
The core Data Science challenge here is to provide a way for common people to see if their symptoms have potential to develop into a much worse fate. To this end, we propose the development and use of a machine learning model that identifies diseases given a certain set of parameters such as age, gender, medical history, lifestyle factors, etc. By using a machine learning model for disease identification, we can leverage the power of data and algorithms to analyze patterns and make predictions based on large databases of medical information. Machine learning models can also learn from new data and feedback and improve their performance over time. This way, we can respond to certain illnesses that would be fatal if left untreated quicker than relying on human judgment alone, increasing human lifespan in the process. Machine learning models can also help diagnose rare or complex diseases that may be difficult for human doctors to identify. Moreover, machine learning models can provide more accessible and affordable healthcare services to people who may not have easy access to medical facilities or professionals.
In order to achieve a working model that can present an accurate prediction, clear and objective data needs to be collected. Important metrics include demographic information, medical history, as well as lifestyle factors. Of these, demographic information and medical history provide a solid foundation of objective data. However, data regarding lifestyle factors is hard to quantify. A questionnaire fulfills the necessary factors in order to ensure that data regarding lifestyle factors is quantifiable and is easy to process. In regards to the questions that will be used, a panel will be put together. This panel will consist of medical experts and researchers from all domains of healthcare. Although a critical part, they will not solely be involved in the making of the questions. An overview of the data breakdown can be seen in below.
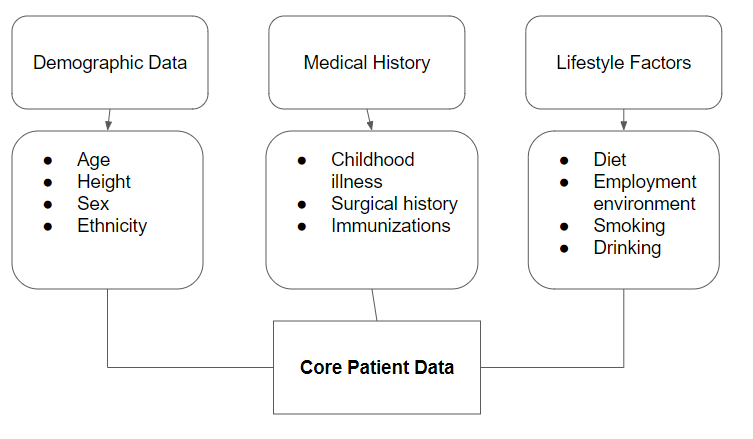
The data will be sourced from current patient records and the ailments they have. This provides us with a solid foundation of training data. This allows us to obtain demographic information and medical history easily using data stored in hospital databases. To gather data regarding lifestyle factors, we will send the patient the questionnaire or have the doctor give them to the patient on their next visit. In the case the patient has passed away, the questionnaire will be given to the patient’s family. If the questionnaire is not filled out or the patient's family declines to provide it, the patient’s data will be removed from the model training data. In addition to this preexisting data, we will want to continuously iterate the model so it is always up to date.
To do so, we will continue to collect medical data and lifestyle data from patients.
The data will be collected from hospitals within the United States as that represents the demographic of the model the best. As such, the data collection process requires the cooperation of a large part of the healthcare sector which becomes difficult to handle. To manage this, the medical experts from the questionnaire panel will be traveling to hospitals where data collection is taking place to ensure that the process is ethical. The main people that will be collecting data will be the nurses and doctors that are in charge of the patients. A high level view of the collection process is seen in the following image.
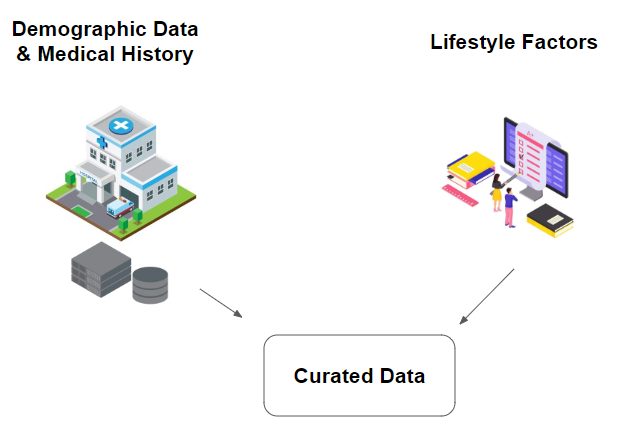
This approach is not without issues however. The largest one, the consent of patients, is important to resolve. Not only is this a HIPAA violation, it is important for participants and patients to be informed about the project. In order to obtain baseline data, we will be working with HIPAA-compliant healthcare institutions that already follow these procedures and guidelines. To further ensure patient consent, we will be informing all patients about the details regarding the project as well as the option to easily withdraw their information from the data that will be used to train the model. Any one who requests the data be withdrawn through the form will be allowed to do so without any extra hassle. In the case of patients that have passed away, the patient's family will have the option to do so.
Another issue to be wary of is the potential for discrimination under the data. This can bias the model to believe a certain classification of disease is applicable to the situation based on the potential patient's demographic but is not necessarily true. Similarly, a more technical issue is the preexisting bias found in the diagnosis of patients. Doctors do not always give the correct diagnosis which is a cause for concern. This is especially true for less known diseases. To mitigate both of these concerns, we will increase sampling and ensure distributions of each case remain approximately the same. In addition, the size of bias in the less known diseases should remain low due to the information received from the sample size.
Before modeling, it is important to see if there are any trends or biases inside the data. To do this, we will have data scientists perform exploratory data analysis to find any trends that may affect the model. To ensure that ethical data science is being performed, all analysis must be readable. However, the work will be confidential due to the nature of the data. The model that we will be using is a random forest classifier. This allows the model’s process to be more apparent. In the case where miss prediction occurs, machine learning engineers will be able to adjust parameters to prevent those mistakes from occurring again. An example of the architecture can be seen below
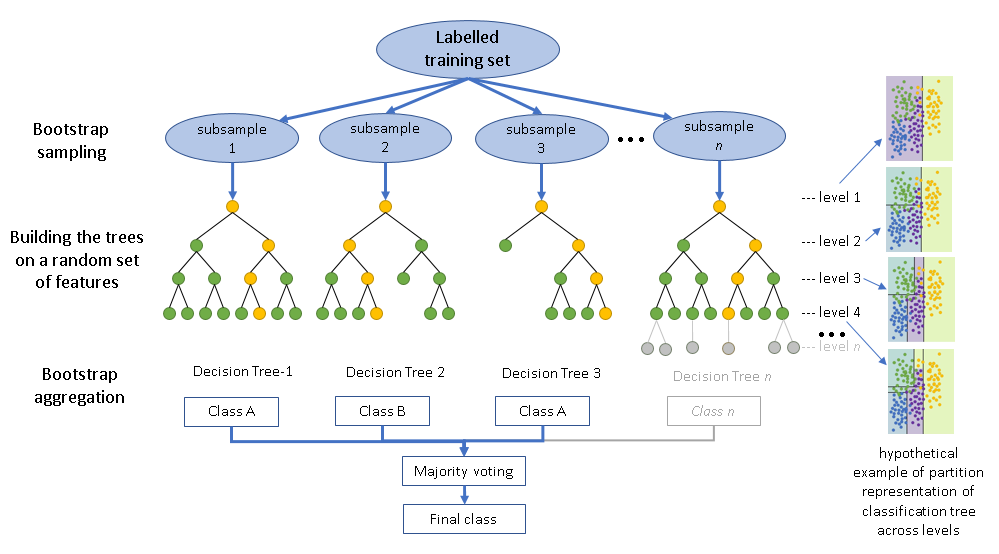
A potential issue that might arise during the analysis phase is the identifying data that is in the dataset. If fallen into the wrong hands, it can lead to a variety of issues, including identity theft. To ensure privacy, there is a two layered approach. The first is that all identifying information like address, social security number, name, etc. will be stripped from the dataset. This gets rid of any explicit identifying features. However, data like age, sex, ethnicity are critical information that can still be identified if someone is able to connect all the dots. This data is extremely important and is a core component of the prediction. For a model based around the health of the user, this can not be removed. To compromise, only authorized users will be allowed to work with the data. Authorized users will need to sign non disclosure and confidentiality agreements to prevent such data from being leaked.
An issue that might arise during the modeling phase is concern over transparency. Patients and stakeholders do not want to see a new black box make claims concerning their health. To assuage those fears, we specifically select a random forest classifier due to the transparent nature of the model. This ensures that stakeholders can see how that decision was reached and what parameters were involved. This model also works well with privacy issues due to the nature of how data is fed into the inputs of the random forest.
The main goal that we aim to achieve through this data science project is to be able to notify people if there is potential for their symptoms to develop into something much worse. To do so, the model is specialized around outputting the diseases or illness that best matches the situation. However, the model is limited by the fact that it is just a model. It does not replace the need for a doctor. The model outputs should not be treated as a diagnosis and those that use the model should not base their treatment on such decisions. To uphold this message, we will always remind the user that consulting a trained professional is always the best option.
One way that the model can be used is by serving as a source of advice. Users of the model can input their symptoms and get a possible diagnosis from the model. Then, they can share these results with a medical professional who can evaluate them further. The doctor can use that information to confirm or challenge their own judgment and make a more informed decision about the best course of treatment. The model can thus act as a helpful tool that offers another perspective on what might be wrong with the patient’s health.
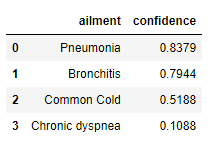
The model will output a table that contains all the information necessary to make a reasonable decision. The format will have two columns: ailment and confidence. The first column, ailment, will contain a list of potential ailments that the model believes best matches the situation. The second column, confidence, contains a float between 0 and 1 which represents the confidence level of that prediction. The table is sorted from largest to smallest confidence levels. To interpret the results, if prediction in the first result is flagged as severe and the confidence level is greater than 0.8, then the application notifies the user to seek medical consultation. For example, the user would be notified that they likely have Pneumonia and to seek medical help in the data returned from the table shown below.
By properly following the instructions laid out, we can ensure justice in two main ways: pivotability and bias. Pivotability means that the model can be easily modified or updated when new data or feedback becomes available. This allows us to address any issues of discrimination or unfairness that may arise from the model’s predictions or decisions. For example, if we find out that the model is giving lower scores to women than men for a certain task, we can quickly pivot the model and adjust its parameters or features so that those effects are removed. Bias means that the model can be intentionally designed to favor certain demographic groups over others in order to increase justice or equity. This involves changing the model’s loss function, which is a measure of how well the model fits the data, to incorporate some form of regularization or penalty for making biased decisions. For example, if we want the model to give higher scores to minority students than majority students for a college admission test, we can add a term to the loss function that penalizes the model for giving lower scores to minority students than their actual performance. By using these two methods of pivotability and bias, we can ensure that our machine learning model is more just and fair for all groups involved.
In addition to this, the model itself is a way to increase justice. The model does this by providing more medical information towards disadvantaged groups who may have less access to quality healthcare or health education. As mentioned before, the model does not serve as a medical professional but it does provide a more indepth perspective into what could be causing their ailments based on their symptoms and history. This can help them to understand their health condition better and make informed decisions about their treatment options. For example, the model can suggest possible diagnoses for a patient who has chest pain and shortness of breath, such as heart attack, angina, or asthma. The model can also explain the risk factors and preventive measures for each condition, such as smoking cessation, exercise, or medication. By providing more medical information to disadvantaged groups, the model can empower them to take charge of their own health and well-being.

There are two main cases for the model to be revised: discrimination and accuracy. As mentioned in the previous section, one of the strong points of the model is that it provides those that are disadvantaged access to health information that they may otherwise lack. However, if the predictions are discriminatory, it conflicts with the justice that was initially provided by the model. In this case there would be a probable cause for the model to be updated or to retire it. An example of this occurring is if the model predicts a higher risk of diabetes for African Americans than Caucasians with similar symptoms. This would indicate that the lost function in the random forest needs to be updated.
The other case, accuracy, is another reason why the model should be updated. As with all models, if accuracy falls below a certain threshold, they need to be updated with new data or algorithms to improve their performance. However, the issue is doubly so for this model. This is because the model may provide a false sense of security by claiming that the ailments will not result in a worse outcome when in reality it could. A case of this occurring is that the model may predict that a user who has a fever and cough has a common cold while in reality they have pneumonia. This could lead the user delaying seeing a medical professional or taking an incorrect medication. This would eventually worsen their condition and put their life at risk.
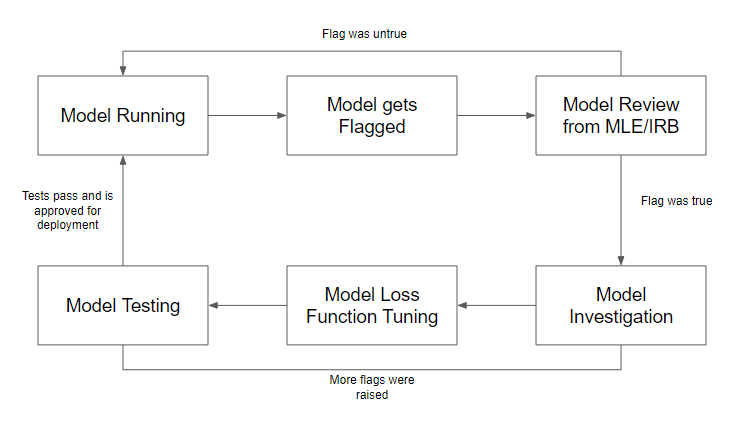
In the case that a model is flagged for discrimination or inaccuracy, a team of machine learning engineers and an institutional review board (IRB) will review whether the flag was correct or not. They will examine the data, the algorithm, and the output of the model to determine if there was any bias or error involved. If it was incorrect, meaning that the model did not violate any ethical or legal standards, there is no intervention and the model will continue to run as usual. However, if it was correct, meaning that the model did discriminate against certain groups or make inaccurate predictions or decisions, there would be an investigation into how the error occurred within the model. The team will identify the source and cause of the problem and propose possible solutions to fix it. After issues are discovered and resolved, the model loss function will be tuned to optimize its performance and reduce its bias or error rate. The loss function is a mathematical formula that measures how well the model fits the data and penalizes it for making wrong predictions or decisions. The model will then undergo testing once again using new data or cross-validation techniques to evaluate its accuracy and fairness. If tests pass, meaning that the model meets the desired criteria and standards, it will be redeployed for production and used by healthcare providers or patients. If tests fail, meaning that the model still has some issues or problems that need to be addressed, it will be revised further until it passes. The entire process can be seen in the flow chart below.